Metamask
Wallet connect
This is a model that can be used to generate and modify images based on text prompts. It is a Latent Diffusion Model that uses two fixed, pretwRAIned text encoders (OpenCLIP-ViT/G and CLIP-ViT/L).
To generates images, enter a prompt and run the model.
SDXL supports in-painting, which lets you "fill in" parts of an existing image with generated content.
Image-to-image lets you start with an input image and transform it "towards" a prompt. For example, you can transform a children's drawing of castle to a photorealistic castle.
With SDXL you can use a separate refiner model to add finer detail to your output.
You can use the refiner in two ways:
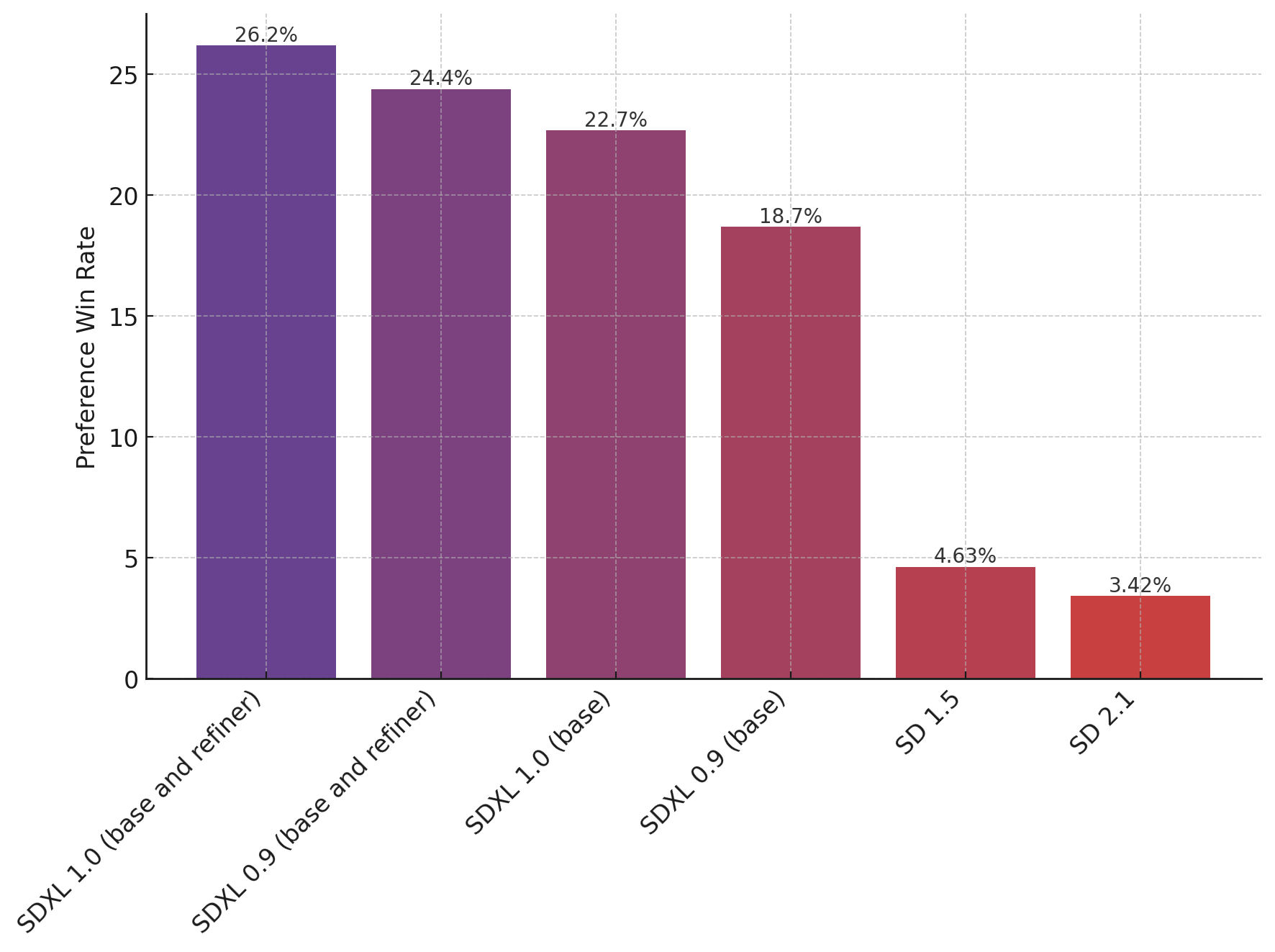
The chart above evaluates user preference for SDXL (with and without refinement) over SDXL 0.9 and Stable Diffusion 1.5 and 2.1. The SDXL base model performs significantly better than the previous variants, and the model combined with the refinement module achieves the best overall performance.
